

Data Loss
Two is one, one is none. That’s the mantra of preparedness right? Recently, I suffered multiple hardware failures on one of my main machines and after working through it, this makes for a great chance to do a bit of a post-mortem and to explore ways to make your data even more resilient.
Quick Links
Timeline of events
For context, since being commissioned, this machine has been running full-tilt nearly continuously, as a media encoding machine.
-
I remote into the machine to check on the encode progress and notice that it is offline. Checking the machine, I see that it has rebooted and was stuck on a ‘No boot devices found/disk not detected. Please fix’ error dialog.
Restarting the machine doesn’t get me past this error message, however, a brief power down (2-seconds) and power up gets me back up and running.
Thinking everything is sorted out, I restart my encode and walk away.
-
A couple hours later, the same thing would happen but this time I checked BIOS and confirmed that the M.2 drive really wasn’t being picked up by the system unless I did a power down.
At this point, we can surmise there is likely a hardware failure of some kind on the primary M.2 drive - perhaps some capacitors are unhappy? This certainly explains why the machine rebooted: Windows was chugging along happy as a clam and then suddenly the OS drive disappears? A reboot is about as graceful as you’re going to get.
When I get back to the desktop, as a precaution, I manually copied a few files there in flux off the machine, onto the network.
-
So the reboot & disk-not-found cycle happens again and this time I power down the machine and pull it out for service. The difference here is that the machine is powered down for longer period (probably 5 minutes for me to disconnect everything and pull it out).
Once it’s out on the table, I can’t get the M.2 to be detected at all. I swap the bays for my two M.2 drives and the primary M.2 is never detected. As a final check, I install a known working M.2 and it’s picked up right away and then I pull the offending M.2 and plug it into a USB NVME enclosure to test on a different machine with no success.
-
Since I had to redo the system anyways, I took this opportunity to do a BIOS update. After replacing the M.2 drive, I set out to rebuild the machine and figure out what data I had lost. Oddly though, I noticed that the freshly installed system was super unstable and would lock-up and BSOD just sitting on the desktop.
The usual culprits for this are excessive overclocks or fault RAM. Since I was getting unprovoked BSODs, this leans on being RAM being faulty. The BIOS update I just did set the overclocking settings back to their off/tame settings so this was another data point suggesting it was the RAM.
To ‘ease up’ on the RAM a bit, I reduced the command rate to 2T and increased the vDIMM a bit. No improvement, still, erratic, unprovoked BSODs. Firing up Memtest confirmed it with a massive battery of failures on Test 8 and a few on Test 13.
After getting the hardware replaced, I was able to get everything back up and running in an afternoon. I think that the two failures are purely by unfortunate coincidence. I’ve started the process for getting the RAM replaced under warranty but I’m going to pass on the warranty for the NVME drive. Corsair’s official policy is to wipe/destroy drives, and while I’m not accusing them of not holding to this policy, the severity is just too high for $300.
What were the parts that failed?
The two devices that failed were the Corsair Vengeance LPX 64GB 3600MHz CL18 kit and the Corsair Force Series MP600 1TB drive. The fact that they are both Corsair products is just an unfortunate coincidence — I would have been perfectly happy to replace these parts with identical parts (although I would probably sprung for the improved MP600 XT.
Purely based on the sale price at the time and stock availability that day, I went with
Teamgroup T-Force Vulcan Z 64G 3600MHz CL18 kit. Obviously it’s too new to be able to determine how well this stacks up, but on paper, it’s ‘the same thing’
WD Black SN850 1TB. On paper, this is substantially faster in every way although both this and my previous drive are just so darn fast that it’s not usually a performance delta you really notice in day to day file copy operations.
As I mentioned, I don’t plan on following up with the RMA process for the drive — it’s not worth the risk to me, but I did start an RMA claim on the RAM. At the time of writing, no update yet: still going back and forth with Corsair support.
How was the drive setup?
The drive that failed was a 1TB Corsair MP600 and I had it split into five partitions:
System
This is my main OS drive and I specifically don’t use any of the “My Folders” (i.e., My Documents, Downloads, Pictures etc.) — all my actual data is squirreled away on its own partition
I do use my desktop as a quick dumping ground for files (since it’s so easy to access with Win+D) so I did make a quick snapshot backup of that during my troubleshooting phase when I started to suspect hardware failure
Since most of this data can be readily rebuilt, I use a LOW backup schedule
Data
Thankfully this drive was mirrored with Synology Drive
Thankfully, I hadn’t made any updates to this drive that weren’t synced
Since this is important stuff, I keep this on a HIGH backup schedule
Dev
This drive didn’t have any automatic syncing setup
This doesn’t see as much churn as it used to, so I keep this on a LOW backup schedule
Thankfully, I hadn’t used this drive in the last few days so there weren’t any changes in limbo
OneNote
I make extensive use of OneNote to keep all sorts of inventory stuff organized; this drive stores the live OneNote document as well as the built-in backups
I have this on a ‘Medium’ backup schedule since the backup also backs up the built-in backups as well
Thankfully, I hadn’t used this drive in the last few days so there weren’t any changes in limbo
Scratch
This partition has both the ingest and output folders for all my media encoding. Data on this drive is generally very temporary: I copy media into the ingest folder to be processed and it is only present on the drive during the encode flow.
Due to how I was using this, this drive isn’t backed up at all so I had to redo a few days worth of encodes



How much data was lost?
Virtually nothing: I lost all of the encode-output files but those can be regenerated as I still have the source files. I’m grateful that I took the time to backup the handful of files that were on my desktop; although not the end of the world, those files would have been lost if I hadn’t did the manual snapshot.
To make the recovery process smoother, I initially copied all of the backups from the network to the local machine (leveraging 10-gig sequential read performance); once the backups were local, the much higher performance of NVME drives makes recovery go by in a hurry.
Improvements for the next time
It’s never fun to think about data loss and planning backups can be really tedious and boring, but the best time to enact these changes is right after getting back up on your feet (or perhaps this is because the sting of potential loss is still fresh on the mind?)
Changes in how I used my drives
Scratch — in the past, I had certain types of transient files go to the desktops (CaptureOne exports, screenshots etc.); now I collect this on the Scratch drive instead — keeps the desktop clutter down
Dev — I moved this directly to the network and leverage Synology Drive to keep my local copy in sync
OneNote — I moved my notebook collection entirely to the network and only keep the local cache on the local drive (in OneNote, the local cache is the live ‘latest copy’ of a given notebook). I also moved the OneNote backups to the network as well, no need to keep that local
Why didn’t I keep OneNote on the network to begin with?
I have an extensive OneNote collection — 100GB spread over eight notebooks or so, so I’ve always wanted to keep as much of it as local as possible to reduce latency. Also for the longest time, I would find myself wanting to access a notebook during really inopportune moments: like when the NAS was powered down or rebooting. More modern versions of OneNote handle local/remote syncing a lot better now so it’s high time to move this stuff to the network.
Changes in the backup strategy
Generally speaking, I upped the pace of updates across the board for data that was more important and slightly reduced backups of files that were already backups of something else:
OneNote already has built-in self-backup capability so I don’t really need to do perpetual backups of it all the time. Because of this, I split the OneNote backup into two schedules:
I still backup the built-in backup files but on a reduced cycle
The live files are backed up more often
One of the big paints in data recovery is when I want a specific file — and to get it, I need to trawl through a massive 70GB archive to extract it. I have a few common things that I definitely want to just have easier access to. To alleviate this hassle, I created a new backup of ‘quick grab files’ which cover these types of files. One additional advantage is that I can build this backup archive from files spread across the whole disk (or multiple disks) and collect them into a single easy place:
C:\UTIL — I keep a lot of content in this folder that I always want to restore including a folder that I throw all sorts of shortcuts into that are linked to a PATH variable
OBS folder & any related plugin-folders
Windows HOSTS file
Selection of files and folders on the Scratch drive
My user account folder — on the off chance I keep something on the desktop etc.
AppData — a lot of apps (annoyingly) put their data here, at least this way I’ll have it
This is a bit of an organic archive: as I notice certain files or folders I use often, I can add this to the quick file backup so that I always have it. From a data recovery perspective, I expect that the ‘quick files’ backup will be a huge improvement to the recovery experience.

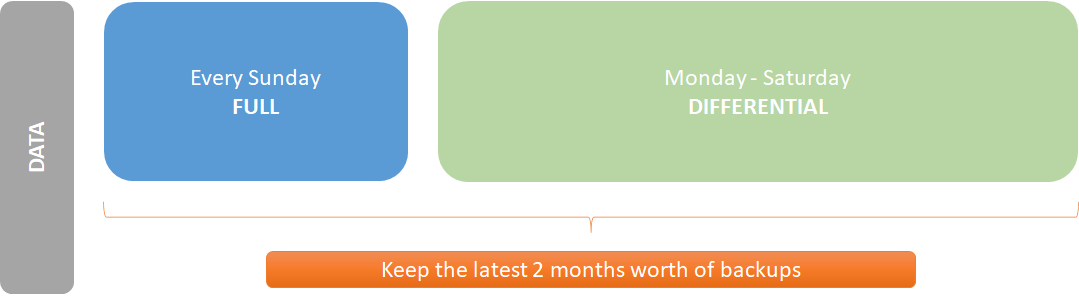




Ok, now what if the NAS fails?
Ah yes, all of these backups are no good if the thing holding them (the NAS) explodes. I have a couple additional layers that should help me out a bit:
Since my system backups already exist on the NAS, it makes sense to leverage the NAS to push the files offsite. The option I went with was to use Glacier Backup to automatically push those backups up to AWS S3 Glacier. The app can be configured to automatically handle rotation and deletion of old backups - it even respects Glacier’s requirement of a minimum of 90-days and automatically queues up deletions as needed. For the time being, I run a 1-year retention for content being pushed offsite.
For me, backups in AWS are ideal when you have a really serious problem, for example, if your house is gone. I don’t store everything up there - just the supercritical stuff. For the ‘run of the mil’ disaster (i.e., where the NAS breaks), I use a SATA docking station to manually backup content.
Why manually?
In an ideal world, the backups would be automatic right? I wish I could do that (and one day, maybe I’ll get there) but short of another target NAS to push everything to, I don’t have a way to backup multiple shared drives across two NAS units to multiple disks. There is an additional requirement that the dock only run only when needed — when the backup completes, I’d to not have the drives running.
This is still a work in progress (limited mostly by purchasing power of getting drives!) but the goal is to eventually have local backups spanning 13 drives or so: one for each month and then the thirteenth drive can either be a reduced or increased frequency (i.e., weekly or yearly). Once the backups are done, wrap each drive in an anti-static bag and put it in a padded drive enclosure, and perhaps put all of those into a watertight hard case. Remember to throw a USB key with the recovery boot environment in there too ;)
What about offsite?
This is always the tricky bit: to a degree, AWS S3 can act as an offsite backup but you could also keep some backups at a friend’s house. There’s a certain degree of reliability and trust required to for that so it may not be for everyone.
Closing thoughts
To streamline the rebuild process, there are things like Ninite which seems really cool but I’m not a fan of ‘default installation settings’ so it’s not a good fit for me. Maybe in the future, there will be a mechanism that allows for end-to-end installation with customization and tweaking (i.e., changing application icons, setting runtime arguments on shortcuts etc.)
What about imaging?
In the enterprise space, they rely on imaging and standardized equipment to get recovery and replacements up and running quickly. For me, this doesn’t necessarily work because hardware failure is usually an opportunity to do hardware upgrades and drastic things like BIOS and firmware updates. In the case of component upgrades, sometimes this means a change of vendors (for example, in the case of an SSD failure) — which means changing the driver/management software. Yes - uninstalling/removing software is a thing, but always feels half-assed when you’ve gone through the effort to get a “new” machine. Put on a tinfoil hat now for a discussion on how uninstalling stuff never really removes it ;)
All in all, I think I got pretty lucky with my component failure and that all of the data I ‘lost’ was already synced and I had multiple backups ready to go. I maintain a pretty thorough repository of all the drivers, utilities, software, tweaks, fixes, patches and exported configuration settings that I use for all machines so it was a pretty low-stress process to get everything rebuilt.
I recognize that I got lucky with the drive failure: had the other drive failed, I would have been a bit more annoyed as I would have lost my games drive; by itself that wouldn’t have been such a big deal, but I had just spent a bunch of time configuring a whole bunch of mods and customizations. Needless to say, I used the opportunity to make sure this content was moved off the local device and backed-up.
Remember: two is one and one is none. Data loss can happen to anyone and sometimes you don’t necessarily get lucky and devices totally hit the crapper. Take the time to ensure that the data you ‘can’t afford to lose’ is protected!
Product links may be affiliate links: MinMaxGeek may earn a commission on any purchases made via said links without any additional cost to you.